geminiann06012 — Announcement
Gemini Science Archive - One Million and Counting
18 May 2006
In recent weeks the Gemini Science Archive (GSA) has passed three significant milestones and attained new levels of use unforeseen in the early days of its development. In this article, we have decided to reflect on the origins of the GSA, its current status in service to the Gemini community, and our plans for its future expansion into the world of the Virtual Observatory (VO).
The first release of the GSA for public use, version 1.0, was in September 2004. At that time we expected its main function to be as a complex data repository, albeit one in which considerable “metadata” was stored along with the observation data. (Metadata is typically information that is itself not of direct scientific importance, but aids in the characterization of the science data. A good example would be data describing weather conditions during an observation run.) We have come a long way in the 18 months since opening public access to the GSA and now view it as a dynamic, crucial, and integral part of Gemini operations, with a future closely linked to observatory-wide dataflow and the international Virtual Observatory development.
A major direction shift in our vision of the GSA occurred with the public release (in May 2005) of what we term PIETD. This acronym stands for “Principal Investigator Electronic Transfer and Distribution.” With this service, we took the first step in moving the GSA from the old model of a science archive—one where it is a static repository for data—to one for the 21st century, where it will directly interact with both observatory operations and users in close to real time. With the latest release of the GSA (version 1.35) in January 2006, we are closer to realizing this vision. The new version includes several different types of data products, such as processed calibrations, and such new features as “Processed Calibration” and “Observing Log” query pages. In addition, with the successful implementation of the “DataManager” software at both telescopes, we now stream raw data from the instruments to the GSA.
The average “ingestion” time for such data is about 30 minutes. This includes on-line ingestion validation and verification, electronic transfer (via a Virtual Private Network link from the Hawai’i and Chile to the Canadian Astronomy Data Centre (CADC) in Victoria, BC, Canada), ingestion into the GSA, and the appearance of the dataset in results pages created through user queries. Of course, all Gemini Queue and Classical data is proprietary for 18 months (the proprietary period is three months for science verification data) but Principal Investigators can download their data using the “Access your PI Data” link via password-protected access. Already several users have downloaded their data within minutes of it appearing in the GSA science tables and fed back useful information on the results obtained to the Gemini the next day!
So, what is the next step for the GSA? The observatory-wide Dataflow Project is driving GSA development in many areas. Our plan is to expand the flow of data into the GSA to include all available processed science products and ancillary metadata files. With the implementation of proposed data quality assessment and control tools, together with modifications and enhancements to the OLDP (On-Line Data Processing system), we hope to be able to quickly provide processed data products to the GSA and (in the near future) to the Canadian Virtual Observatory, our adopted portal to the VO. Our hope is that, within the next few years, to provide processed data products to Principal Investigators via the VO including, for example, source catalogs, so that recipients of Gemini data can work immediately on the scientific content of their data. Now, back to the milestones. As we mentioned above, the GSA achieved three significant milestones earlier this year. We are confident that these are the first of many more to come. Yet they serve to mark the rapid growth in content, usage, and usefulness of the GSA, to the Gemini community and astronomers worldwide, as well as the rapidly evolving sophistication of GSA operations at CADC.
The first milestone was, as the title of this article suggests, the one millionth file ingested into the GSA. This number truly represents the maturing of the Gemini telescopes and the dedication of so many staff members to the goal of the efficient collection of astronomical data. These one million files are our “complete collection,” yet include close to 200,000 individual science datasets, together with extensive calibration data and metadata files. As of April 1, 2006, the GSA science collection has more than 112,000 public datasets, with more being released every day.
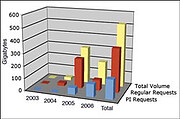
The second milestone is related to the first although expresses a somewhat different message. The content of the GSA has recently exceeded three terabytes in size. Again, this is the complete collection of data stored in the GSA, yet it represents a growth trend unforeseen in the early days of the design of the GSA. The GSA is now the third-largest collection hosted by CADC (behind CFHT and HST) and will likely continue to grow at an accelerating rate as more and varied data products are made available.
The final milestone we note here is the 300th registered user of the GSA. The number of users has been growing rapidly, particularly after the release of PIETD. However, retrieval statistics show that PI requests are still a factor of two smaller than those of general non-PI users. Already the total number of PI requests in the first three months of 2006 have matched the total PI requests in the whole of 2005! To conclude, the future of the GSA is very bright and we look forward to reporting on the next stages of GSA development soon.
Contacts
Colin Aspin
Staff Scientist at the Gemini Observatory (Hilo, Hawai‘i) Email: caspin@gemini.edu
About the Announcement
| Id: | geminiann06012 |
Images
{kind=link}