

La IA se une a la búsqueda de tesoros cósmicos en un océano de datos
Astrónomos aplican técnicas de aprendizaje automático para descubrir cuásares del Universo temprano ocultos en datos de archivo del estudio Dark Energy Survey
Perfil
Nombre: Telescopio de 4 metros Víctor M. Blanco
Ubicación: Observatorio Cerro Tololo
Diseño óptico: Ritchey-Chretien Cassegrain
Diámetro del espejo primario: 4 metros
Banda de frecuencia operacional: Óptica/infrarrojo cercano
Primera luz: 1976
Altitud: 2.207 metros
Nombre: Gemini Sur
Ubicación: Cerro Pachón, Chile
Diseño óptico: Ritchey-Chrétien Cassegrain
Diámetro del espejo primario: 8,1 metros
Banda de frecuencia operacional: Óptica/infrarroja
Primera luz: 2000
Altitud: 2.737 metros
Metas de ciencia:
- Telescopios gemelos en ambos hemisferios entregan acceso a todo el cielo a los miembros participantes
- Entregar la mejor calidad de imagen posible desde tierra para telescopios de su tamaño
- Entregar telescopios capaces de proveer las imágenes más nítidas posibles para observaciones infrarrojas desde el suelo terrestre
10 Jul. 2024
Los cuásares son núcleos galácticos extremadamente luminosos donde el gas y el polvo caen en un agujero negro supermasivo central y emiten enormes cantidades de luz. Debido a su brillo excepcional, estos objetos pueden verse a altos desplazamientos al rojo, es decir, a grandes distancias. Un desplazamiento al rojo más alto no sólo indica que un cuásar se encuentra a mayor distancia, sino también más atrás en el tiempo. A los astrónomos les interesa estudiar estos objetos antiguos porque contienen pistas sobre la evolución de nuestro Universo en su primera adolescencia.
¿Sabías que… según un estudio de 2024, el objeto más brillante conocido en el Universo es un cuásar alimentado por el agujero negro con el crecimiento más rápido del que se tiene registro?
Los candidatos a cuásar de alto desplazamiento al rojo se identifican inicialmente por su color —son muy rojos— y deben confirmarse como tales mediante observaciones separadas de sus espectros. Sin embargo, algunos candidatos a alto desplazamiento al rojo podrían descartarse erróneamente de la investigación debido a distorsiones en su apariencia causadas por lentes gravitacionales. Se trata de un fenómeno que se produce cuando un objeto masivo, como una galaxia, se sitúa entre nosotros y un objeto lejano. La masa de la galaxia curva el espacio y actúa similar a una lupa, haciendo que la trayectoria que sigue la luz del objeto lejano se doble y resulte en una imagen distorsionada del objeto.

Si bien esta alineación puede ser beneficiosa —un lente gravitacional amplifica la imagen del cuásar, haciéndolo más brillante y fácil de detectar—, también puede alterar engañosamente su aspecto. La interferencia de la luz de las estrellas en la galaxia que actúa como lente puede hacer que el cuásar parezca más azul, mientras que la curvatura del espacio-tiempo puede hacer que parezca difuminado o multiplicado. Ambos efectos hacen probable su eliminación como candidato a cuásar.
Fue así que un equipo de astrónomos dirigido por Xander Byrne, astrónomo de la Universidad de Cambridge y autor principal del artículo que presenta estos resultados en la revista Monthly Notices of the Royal Astronomical Society, se propuso recuperar los cuásares vistos con lente que se habían pasado por alto en estudios anteriores.
Byrne emprendió la caza de estos tesoros perdidos en el extenso archivo de datos del estudio Dark Energy Survey (DES). DES se llevó a cabo con la Cámara de Energía Oscura fabricada por el Departamento de Energía de EE.UU. y montada en el Telescopio Víctor M. Blanco de 4 metros del Observatorio Cerro Tololo de la Fundación Nacional de Ciencias de EE.UU., un Programa de NOIRLab de NSF. De esta forma, el desafío consistía en idear una forma de descubrir estas joyas cósmicas entre el enorme océano de datos.
El aprendizaje automático consiste en encontrar los fragmentos de datos que son útiles.
El conjunto de datos de DES incluye más de 700 millones de objetos. Byrne redujo este archivo comparando los datos con imágenes de otros estudios para filtrar los candidatos menos probables, incluyendo los objetos que probablemente eran enanas café, que, a pesar de ser completamente diferentes de los cuásares en casi todos los sentidos, pueden parecer sorprendentemente similares a los cuásares en las imágenes. Este proceso permitió obtener un conjunto de datos mucho más manejable de 7.438 objetos.

Byrne necesitaba maximizar la eficiencia en la búsqueda de esos 7.438 objetos, pero sabía que las técnicas tradicionales probablemente pasarían por alto los cuásares de alto desplazamiento al rojo que buscaba: “Para no descartar prematuramente los cuásares vistos con lente, aplicamos un algoritmo de aprendizaje contrastivo que funcionó de maravilla”, explicó.
El aprendizaje contrastivo es un tipo de algoritmo de inteligencia artificial (IA) en el que las decisiones secuenciales colocan cada punto de datos en un grupo en función de lo que es o lo que no es. “Puede parecer magia, pero el algoritmo no utiliza más información que la que ya contienen los datos. El aprendizaje automático consiste en encontrar los fragmentos de datos que son útiles”, explica Byrne.
La decisión de Byrne de no depender de la interpretación visual humana le llevó a plantearse un proceso de IA no supervisado, lo que significa que el propio algoritmo dirige el proceso de aprendizaje en lugar de un humano.
Los algoritmos de aprendizaje automático supervisado se basan en la llamada verdad fundamental, definida por un programador humano. Por ejemplo, el proceso puede empezar con la descripción de un gato y pasar por decisiones como “esto es/no es una imagen de un gato. Esto es/no es una imagen de un gato negro”. En cambio, los algoritmos no supervisados no se basan en esa definición inicial especificada por el ser humano. En su lugar, el algoritmo ordena cada punto de datos en función de las similitudes con los demás puntos de datos del conjunto. En este caso, el algoritmo encontraría similitudes entre las imágenes de varios animales y las ordenaría en grupos de gatos, perros, jirafas, pingüinos, etc.
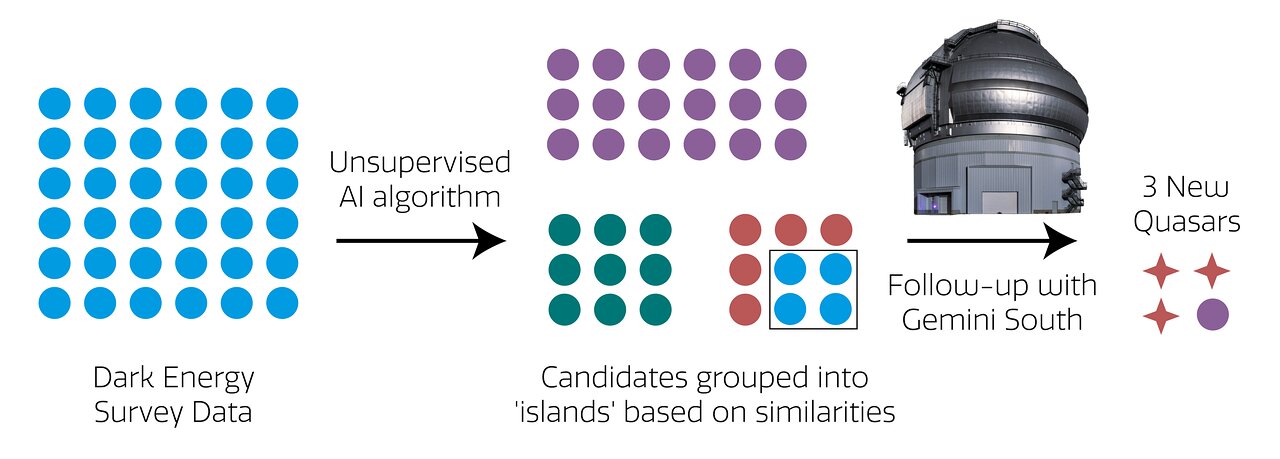
Partiendo de los 7.438 objetos de Byrne, el algoritmo no supervisado clasificó los objetos en grupos. Utilizando una analogía geográfica, el equipo se refirió a las agrupaciones de datos como un archipiélago (el término no implica ninguna proximidad espacial entre los objetos. Son sus características las que los agrupan “cerca”, no sus posiciones en el cielo). Dentro de este archipiélago, se agrupó un pequeño subconjunto “insular” de objetos como posibles candidatos a cuásar. Entre esos candidatos, cuatro destacaban como gemas en un montón de piedritas.
Si esta búsqueda se hubiera realizado con métodos de búsqueda estándar, es probable que esta joya hubiese permanecido oculta.
Mediante datos de archivo del telescopio Gemini Sur, una mitad del Observatorio Internacional Gemini, financiado en parte por la NSF y operado por NOIRLab de la NSF, Byrne confirmó que tres de los cuatro candidatos de la “isla de los cuásares” son efectivamente cuásares de alto desplazamiento al rojo. Y es muy probable que uno de ellos sea la recompensa cósmica que Byrne esperaba encontrar: un cuásar de alto desplazamiento al rojo visto con lente gravitacional. El equipo ahora planea realizar imágenes de seguimiento para confirmar la naturaleza “amplificada” del cuásar.
“Si se confirma, el descubrimiento de un cuásar visto con lente en una muestra de cuatro objetivos sería un porcentaje de éxito extraordinariamente alto. Y si esta búsqueda se hubiera realizado con métodos de búsqueda estándar, es probable que esta joya hubiese permanecido oculta”.
El trabajo de Byrne es un ingenioso ejemplo de cómo la IA podría ayudar a los astrónomos en su búsqueda entre cofres de datos cada vez más grandes. En los próximos años, se espera una afluencia masiva de datos astronómicos gracias al estudio de cinco años del Instrumento Espectroscópico para el Estudio de la Energía Oscura y la próxima Investigación del Espacio-Tiempo como Legado para la posteridad (LSST, por sus siglas en inglés), que llevará a cabo el Observatorio Vera C. Rubin a partir del año 2025.
Enlaces
